
nakka soft world !
[Python] Pandas dataframe txt로 저장하기 본문
Python으로 작업을 하다 보면 파일로 저장하고 싶은 욕구가 생길때가 한 두 번이 아니다.
Dataframe을 다룰때도 마찬가지 입니다.
Dataframe을 다뤄 본 사람들이라면 csv나 xlsx로 저장하는 api가 있기에 해당 형식으로는 종종 저장 해봤을 것이다.
(.to_csv와 .to_excel)
csv나 xslx파일 포멧도 좋지만, 이 파일들은 꼭 엑셀로 연결이 되어있어 엑셀로 열린다.
엘셀이 실행될때의 답답함이란....
그렇다면 txt로 저장해서 메모장으로 열리게 할 수는 없을까?
이 포스팅이 이에 대한 해답니다.
처음에는 open으로 파일을 열고 한줄한줄 wirte해야하나 싶었는데, 매우 간단히 해결되었다.
# Sample Dataframe
import pandas as pd
df = pd.DataFrame({'Kind':['과자','음료','라면','빵'],
'Price':['15000','2500','5200','1600']})
print(df)
이제 본격적으로 저장을 해본다.
사실 매우 간단한거라 포스팅을 해야 하나 많은 고민을 했는데, 혹시나 나와 같은 고민을 하는 사람들을 위해서 포스팅을 하게 되었다.
Dataframe을 to_cvs api로 저장하지만 파일 명을 .txt로 지정
df.to_csv('sample.txt')to_cvs의 parameter로 파일명을 넣어 줄 수 있는데, 이떄의 파일명을 .txt로 지정한다.
그렇게 되면 아래와 같이 cvs형식의 text로 저장이 된다.
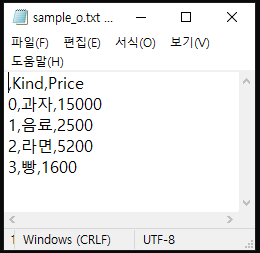
이제 부터는 좀 이쁘게 꾸며 보자.
콤마(,)를 탭으로 변경.
# 콤마응 탭으로 치환
df.to_csv('sample_tab.txt', sep = '\t')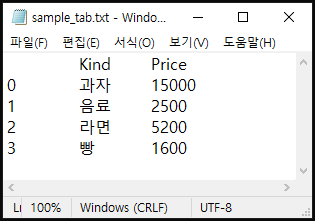
음... 아까 보단 보기가 편해 졌네요.
근데, 앞에 0 1 2 3이 좀 보기 거슬리네요. 없었으면 좋겠는데....
Index 없애기
# Index 없애기
df.to_csv('sample_noidx.txt', sep = '\t', index = False)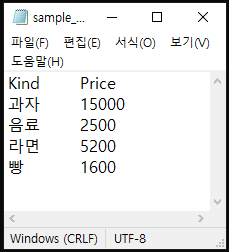
오늘은 DataFrame을 메모장에서 읽기 가능한 파일로 저장하는 방법에 대해서 포스팅 했습니다.
별내용이 없어, DataFrame의 to_cvs()함수의 추가적인 내용도 알아 보았는데요.
to_cvs()함수는 이보다 강력한 기능들을 많이 제공 합니다.
아래 API를 보시고 필요한 Paramater로 DataFrame을 저장하시면 됩니다.
DataFrame.to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression='infer', quoting=None, quotechar='"', line_terminator=None, chunksize=None, date_format=None, doublequote=True, escapechar=None, decimal='.', errors='strict')
그럼 즐거운 코딩의 시계로 다시 들어 가 봅시다.
# 최종 코드
import pandas as pd
df = pd.DataFrame({'Kind':['과자','음료','라면','빵'],
'Price':['15000','2500','5200','1600']})
print(df)
df.to_csv('sample_o.txt')
df.to_csv('sample_tab.txt', sep = '\t')
df.to_csv('sample_noidx.txt', sep = '\t', index = False)'프로그래밍언어 > Python' 카테고리의 다른 글
| Oracle Cloud에 Flask 서버 구축 (0) | 2024.06.02 |
|---|---|
| [Python] 디렉토리 관련 명령어 (0) | 2021.06.07 |
| dart-fss를 활용하여 기업 재무 재표 가져 오기 (0) | 2020.12.22 |
| Global 변수 값 변경 (0) | 2016.09.24 |
| [Python] Bubble sort (0) | 2015.07.07 |


